经常在网上看到这道题目,写一篇博客记录一下。
后端传数据和前端接收数据的代码都省略了,直接看重点:怎么将这些数据渲染出来?
1. 常规方案
最常规的方案就是接收到数据之后在容器中逐条创建:
const renderList = async () => {
// 调用函数获取到10w条数据
const list = await getList();
// 逐条读取并插入到容器中
list.forEach(item => {
const div = document.createElement('div')
div.className = 'flex'
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`
container.appendChild(div)
});
}
毫无疑问这种方法是不可取的,数据量小还好,数据量一大起来那耗费的时间和资源是巨大的。
2. 优化一 前端分页
思路是把10w条数据分成10w/200 = 500页,通过setTimeout每次只渲染一页,速度大幅提升。
const renderList = async () => {
const list = await getList();
// 总数据条数
const total = list.length;
// 每页数据条数
const limit = 200;
// 总页数
const totalPage = Math.ceil(total / limit);
// 用于遍历的页数
const page = 0;
const render = (page) => {
if (page >= totalPage) return ;
setTimeout(() => {
// 逐页渲染
for (let i = page * limit; i < page * limit + limit; i++) {
const item = list[i];
const div = document.createElement('div')
div.className = 'flex'
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`
container.appendChild(div)
}
render(page + 1)
}, 0)
}
render(page);
}
3. 优化二 requestAnimationFrame
别的全部没区别,就把setTimeout改成requestAnimationFrame,减少了重排的次数,极大提高了性能。
requestAnimationFrame(() => {
// 逐页渲染
for (let i = page * limit; i < page * limit + limit; i++) {
const item = list[i];
const div = document.createElement('div')
div.className = 'flex'
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`
container.appendChild(div)
}
render(page + 1)
})
什么是requestAnimationFrame?
window.requestAnimationFrame() 告诉浏览器:
- 你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。
- 该方法需要传入一个回调函数作为参数,该回调函数会在浏览器下一次重绘之前执行
- 若你想在浏览器下次重绘之前继续更新下一帧动画,那么回调函数自身必须再次调用window.requestAnimationFrame()
上面概念太抽象了,那到底和setTimeout区别在哪?
用法其实跟 setTimeout 完全一致,只不过当前的时间间隔是跟着系统的绘制频率走,是固定的。
优点在于:
- 减少DOM操作
requestAnimationFrame 会把每一帧中的所有 DOM 操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率 - 资源节能
requestAnimationFrame 是由浏览器专门为动画提供的 API,在运行时浏览器会自动优化方法的调用,并且如果页面不是激活状态下的话,动画会自动暂停,有效节省了 CPU 开销 - 函数节流
在高频率事件( resize, scroll 等)中,为了防止在一个刷新间隔内发生多次函数执行,RequestAnimationFrame可保证每个刷新间隔内,函数只被执行一次,这样既能保证流畅性,也能更好的节省函数执行的开销,一个刷新间隔内函数执行多次时没有意义的,因为多数显示器每16.7ms刷新一次,多次绘制并不会在屏幕上体现出来。
setTimeout执行动画容易出现卡顿、抖动的现象。原因是:
- settimeout任务被放入异步队列,只有当主线程任务执行完后才会执行队列中的任务,因此实际执行时间总是比设定时间要晚;
- settimeout的固定时间间隔不一定与屏幕刷新间隔时间相同,会引起丢帧。
requestAnimationFrame 采用 浏览器时间间隔 ,保持最佳绘制效率,不会因为间隔时间过短,造成过度绘制,消耗性能;也不会因为间隔时间太长,造成动画卡顿不流畅
4. 优化三 DocumentFragments
之前的代码中每创建一个div就立刻插入到container中:
// ...
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`
container.appendChild(div)
那么是否可以改成一次性添加到container中呢?通过DocumentFragments来实现:
const renderList = async () => {
const list = await getList();
// 总数据条数
const total = list.length;
// 每页数据条数
const limit = 200;
// 总页数
const totalPage = Math.ceil(total / limit);
// 用于遍历的页数
const page = 0;
const render = (page) => {
if (page >= totalPage) return;
requestAnimationFrame(() => {
// 创建文档片段
const fragment = document.createDocumentFragment()
// 逐页渲染
for (let i = page * limit; i < page * limit + limit; i++) {
const item = list[i];
const div = document.createElement('div')
div.className = 'flex'
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`
// 将div插入到文档片段
fragment.appendChild(div)
}
// 将文档片段插入到dom树
container.appendChild(fragment)
render(page + 1)
})
}
render(page);
}
DocumentFragments,这个又是啥?
- DocumentFragments 是DOM节点。它们不是主DOM树的一部分。通常的用例是创建文档片段,将元素附加到文档片段,然后将文档片段附加到DOM树。
- 在DOM树中,文档片段被其所有的子元素所代替。因为文档片段存在于内存中,并不在DOM树中。
- 所以将子元素插入到文档片段时不会引起回流,因此,使用文档片段通常会带来更好的性能。
5. 优化四 懒加载
不过那篇博客主要涉及的是组件懒加载,这种内容懒加载主要还是通过getBoundingClientRect或者IntersectionObserver
来监听位置,当内容进入到可视区后再加载。
具体实现之后有空补充,重点学习下面的虚拟列表。
6. 优化五 虚拟列表
6.1 子项定高
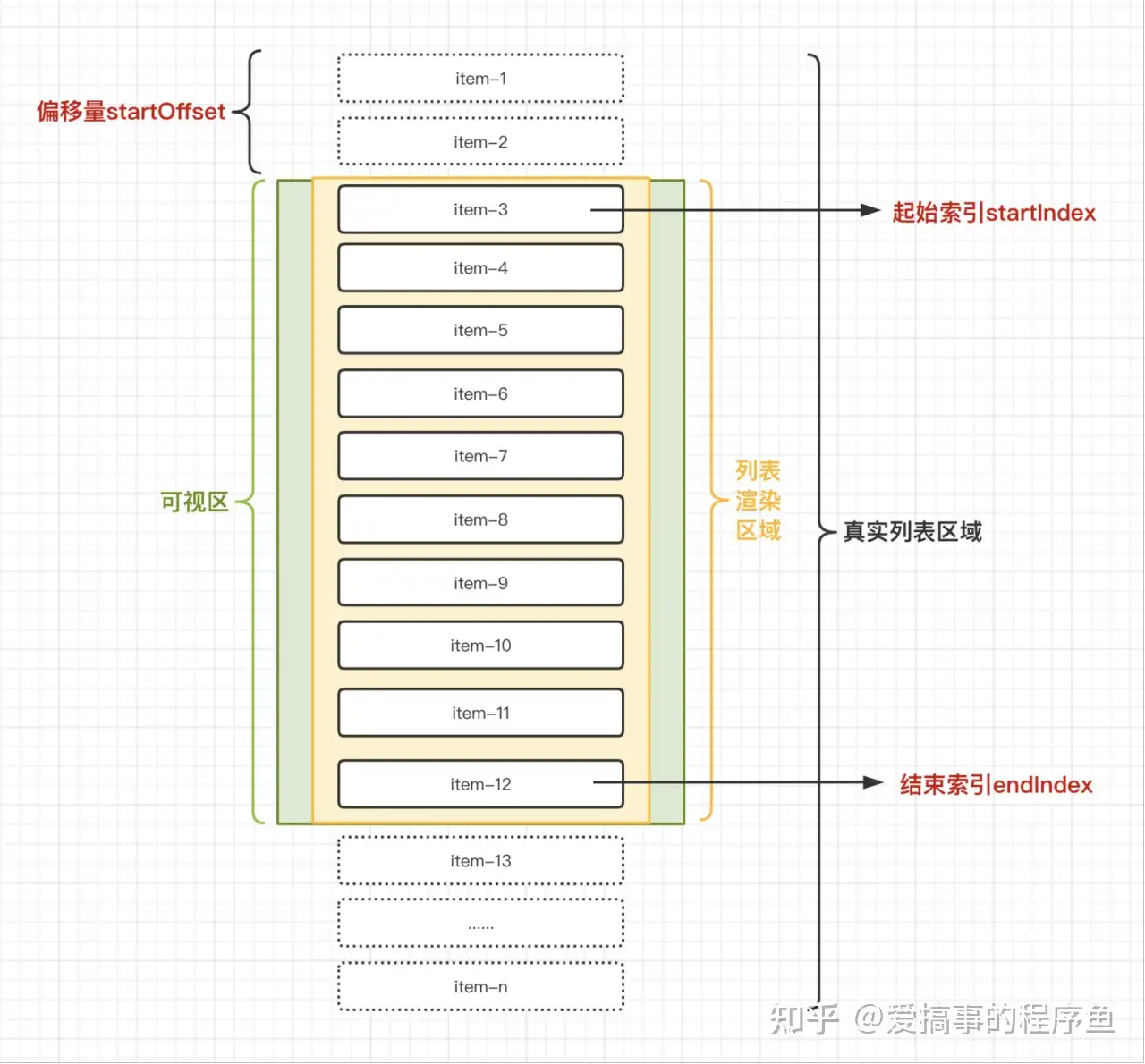
相对来说最合理的优化方法:只对可见区域进行渲染,对非可见区域中的数据不渲染或部分渲染的技术,从而达到极高的渲染性能,虚拟列表其实是按需显示的一种实现。(参考)
和懒加载的区别就体现在当内容出了可视区后会被销毁,毕竟懒加载迟早还是会把所有内容加载下来,可能还是会导致交互的卡顿。
这里首先把完整的实现代码贴上来然后分析:
App.jsx
import VList from "./components/vlist";
let data = [];
for (let id = 0; id < 1000; id++) {
data.push(id);
}
export default function App() {
return (
<div className="App">
<VList list={data}></VList>
</div>
);
}
主页面,引入虚拟列表组件并且模拟1000条数据,将模拟的数据通过prop传递过去。
核心代码 Vlist.jsx
import React, { useMemo, useRef, useState } from "react";
import "./vlist.css";
export default function Vlist(props) {
const { list = [] } = props;
const viewport = useRef(null); // 可视区域
const listArea = useRef(null); // 渲染区域
const phantom = useRef(null); // 占位区域,列表总高度
// 每项列表的高度
const itemSize = 100;
// 列表总高度
const phantomHeight = list.length * itemSize;
// 渲染数量
const viewCount = 10;
// 开始index
const [startIndex, setstartIndex] = useState(0);
// 结束index
const endIndex = useMemo(() => startIndex + viewCount, [startIndex]);
// 偏移量
const [startOffset, setstartOffset] = useState(0);
// 获取startIndex
const getStartIndex = (scrollTop) => {
return Math.floor(scrollTop / itemSize);
};
// 获取startOffset
const getStartOffset = (startIndex) => {
return startIndex * itemSize;
};
// 是否在可视区域内
const isBetweenViewRanges = (index) => {
return index >= startIndex && index <= endIndex;
};
/**
* 获取滚动距离 scrollTop
* 根据 scrollTop 和 itemSize 计算出 startIndex 和 endIndex
* 根据 scrollTop 和 itemSize 计算出 startOffset
* 显示startIndex 和 endIndex之间的元素
* 设置listArea的偏移量为startOffset
*/
const onScroll = () => {
const scrollTop = viewport.current.scrollTop; // 滚动距离
const startIndex = getStartIndex(scrollTop);
setstartIndex(startIndex);
const startOffset = getStartOffset(startIndex);
setstartOffset(startOffset);
};
return (
// 可视区
<div className="viewport" ref={viewport} onScroll={onScroll}>
{/* 占位区 用于显示滚动条 需脱离文档流 */}
<div
className="list-phantom"
ref={phantom}
style={{ height: `${phantomHeight}px` }}
></div>
{/* 列表区 */}
<div
className="list-area"
ref={listArea}
style={{ transform: `translate3d(0,${startOffset}px,0)` }}
>
{list.map((item, index) =>
isBetweenViewRanges(index) && (
<div
key={item.id}
className="list-item"
style={{ height: itemSize + "px", lineHeight: itemSize + "px" }}
>
{item.id}
</div>
)
)}
</div>
</div>
);
}
具体逻辑看参考文章,这里写一下几个需要理解的点:
- 占位区的作用: 如果只渲染出可视区内的item那显然不足以把滚动条撑开实现持续滚动,需要有一个盒子将整个区域撑开,高度设置为列表总高度,便于模拟“滚动”的过程(实际上可视区内容是计算出来的)。但是这个盒子必须是“隐形”的,否则会占据文档流空间,因此通过设置绝对定位使得占位区盒子脱离文档流即可。
- translate3d: mdn,这里的作用就是移动y坐标而已(那么为啥不用translate呢,其实都一样,写法区别而已)
- startOffset: 这个偏移量的作用是让可视窗口移动到被渲染出来的数据的位置。因为实际上当前窗口中展示的数据内容是通过startIndex和endIndex被计算出来的,而非像传统的滚动那样滚出来的。因此必须要让可视窗口也移动到被计算出来的数据所在的位置。

6.2 子项不定高
不定高分为两种处理方式,其一是提前计算好子项的所有高度,然后当做定高来处理;其二是采取动态获取高度的方式来计算,也就是滚到某个位置时,动态计算其中子项的高度。

具体逻辑见参考文章,已经说得很清楚了,这里还是上代码然后分析:
VList.js
import React, { useEffect, useMemo, useRef, useState } from "react";
export default function Vlist(props) {
const { list = [] } = props;
const viewport = useRef(null); // 可视区域
const listArea = useRef(null); // 渲染区域
const phantom = useRef(null); // 占位区域,列表总高度
// 预估高度
const defaultItemSize = 100;
// 记录列表项的位置信息
const [positions, setpositions] = useState(
list.map((item, index) => {
return {
index,
height: defaultItemSize,
top: index * defaultItemSize,
bottom: (index + 1) * defaultItemSize
};
})
);
window.positions = positions;
// 列表总高度
const [phantomHeight, setphantomHeight] = useState(
positions.reduce((total, item) => total + item.height, 0)
);
const viewCount = 10; // 渲染数量
const [startIndex, setstartIndex] = useState(0); // 开始index
// 结束index
const endIndex = useMemo(() => startIndex + viewCount, [startIndex]);
const [startOffset, setstartOffset] = useState(0); // 偏移量
useEffect(() => {
if (positions?.length) {
const totalHeight = positions.reduce(
(total, item) => total + item.height,
0
);
setphantomHeight(totalHeight);
}
}, [positions]);
// 测量高度
const measure = (index, height) => {
// 如果没有传入height,主动进行测量
if (height === undefined) {
height =
listArea.current.querySelector(`[index="${index}"]`)?.clientHeight ||
defaultItemSize;
}
positions.forEach((item) => {
if (item.index === index) {
let oldHeight = item.height;
let dHeight = oldHeight - height;
// 向下更新
if (dHeight) {
item.height = height;
item.bottom = item.bottom - dHeight;
for (let k = index + 1; k < positions.length; k++) {
positions[k].top = positions[k - 1].bottom;
positions[k].bottom = positions[k].bottom - dHeight;
}
}
}
});
setpositions(positions);
};
// 获取startIndex 二分查找法
const getStartIndex = (scrollTop) => {
let item = positions.find((i) => i && i.bottom > scrollTop);
return item.index;
};
// 获取startOffset
const getStartOffset = (startIndex) => {
return startIndex >= 1 ? positions[startIndex - 1].bottom : 0;
};
/**
* 获取滚动距离 scrollTop
* 根据 scrollTop 和 itemSize 计算出 startIndex 和 endIndex
* 根据 scrollTop 和 itemSize 计算出 startOffset
* 显示startIndex 和 endIndex之间的元素
* 设置listArea的偏移量为startOffset
*/
const onScroll = () => {
const scrollTop = viewport.current.scrollTop; // 滚动距离
const startIndex = getStartIndex(scrollTop);
setstartIndex(startIndex);
const startOffset = getStartOffset(startIndex);
setstartOffset(startOffset);
};
return (
<div className="viewport" ref={viewport} onScroll={onScroll}>
<div
className="list-phantom"
ref={phantom}
style={{ height: `${phantomHeight}px` }}
></div>
<div
className="list-area"
ref={listArea}
style={{ transform: `translate3d(0,${startOffset}px,0)` }}
>
{list.map(
(item, index) =>
index >= startIndex &&
index <= endIndex &&
props.children({
index,
item,
measure
})
)}
</div>
</div>
);
}
说一下和上面定高子项不同的点:
- 引入列表项的position这个state,position存储了每个字项的下标,高度,顶部和底部的位置。
- 由于子项不定高,因此列表总高度也必须在useEffect中依赖子项高度计算出来,并分配给占位div。
- 在measure函数中实现动态测量高度的功能,首先通过传入的高度参数/clientHeight/defaultItemSize得到子项的高度。随后判断该子项高度是否大于原本高度(注意上面代码里的dHeight显然是负数,所以bottom才会去减dHeight”,相当于bottom值增加,也就是下移),同时更新自身bottom的值与下方所有子项的top和bottom。
- 最后模版处的区别,这里在列表区留下了插槽,插槽装的内容下文讲解。
item.jsx
import React, { useEffect, useRef } from "react";
export default function Item(props) {
const { index, measure } = props;
const element = useRef(null);
useEffect(() => {
measureItem(index);
}, []);
// 这里负责纯文本的渲染 直接传clientHeight进去
const measureItem = (index) => {
const item = element.current;
if (item?.clientHeight) {
measure(index, item.clientHeight);
}
};
return (
<div index={index} className="list-item" ref={element}>
{props.children}
</div>
);
}
这里主要负责文本内容的渲染,然后留下了一个插槽,插槽内容见下文。
App.jsx
import "./styles.css";
import VList from "./components/vlist";
import Item from "./components/item";
import faker from "faker";
let data = [];
for (let id = 0; id < 100; id++) {
const item = {
id,
value: faker.lorem.paragraphs() // 长文本
};
if (id % 5 === 1) {
item.src = faker.image.image();
}
data.push(item);
}
export default function App() {
// 开启图片
const enableImag = true;
return (
<div className="App">
<VList list={data}>
{({ index, item, measure }) => (
<Item index={index} key={item.id} item={item} measure={measure}>
<>
{item.value}
{enableImag && item.src && (
<img src={item.src} onLoad={() => measure(index)} alt="" />
)}
</>
</Item>
)}
</VList>
</div>
);
}
除了基本的插入id和长文本外,还通过依赖随机生成了图片,而图片则是放到刚刚item组件的插槽中,并且会动态计算出高度。
6.3 优化
6.3.1 IntersectionObserver
传统方法是通过监听scroll事件来判断子项的位置。然而太多的事件监听会导致性能和交互体验等各方面的问题,因此考虑通过IntersectionObserver这个api来进行子项的位置监听。
IntersectionObserver可以监听目标元素是否出现在可视区域内,在监听的回调事件中执行可视区域数据的更新,并且IntersectionObserver的监听回调是异步触发,不随着目标元素的滚动而触发,性能消耗极低。
6.3.2 ResizeObserver
如果列表项中包含图片,并且列表高度由图片撑开,由于图片会发送网络请求,此时无法保证我们在获取列表项真实高度时图片是否已经加载完成,从而造成计算不准确的情况。
这种情况下,最好主动去监听子项的高度,这里用到ResizeObserver这个api。
// 监听高度变化
const observe = () => {
const resizeObserver = new ResizeObserver(() => {
// 获取当前列表项的高度
const el = element.current;
if (el && el.offsetHeight) {
// 触发更新
measure(index, el.offsetHeight);
}
});
resizeObserver.observe(element.current);
return () => resizeObserver.disconnect();
};
6.3.3 缓冲区
这个比较好理解,就是计算的时候上上下下多算几条作为缓冲,避免划太快的时候白屏。至于缓冲区的大小怎么规定就要看具体问题具体决定了。
const endIndex = useMemo(
() => Math.min(startIndex + viewCount + buffered, list.length),
[startIndex, list.length]
);
6.3.4 骨架屏
采用骨架屏代替原先不渲染的白屏部分,提升用户体验。

6.3.5 二分查找startIndex
显然positions数组是有序数组,因此可以通过二分查找来优化时间复杂度。先来看之前的,是直接通过find方法来寻找:
const getStartIndex = (scrollTop) => {
let item = positions.find((i) => i && i.bottom > scrollTop);
return item.index;
};
优化后可以通过二分算法直接寻找出index(二分算法这里就不展开了):
const getStartIndex = (scrollTop) => {
let item = binarySearch(positions, scrollTop);
return Math.max(0, item - buffered);
};
6.4 实习项目中的实际应用
有了上面的理论铺垫,实际应用起来其实就没那么难了,但是实际中和案例还是有一些区别:
-
上面的例子中是通过一个占位区div来撑开整个列表高度的,表格中显然不能用这个方法,因此需要固定表头,才能使得表格的内容形成滚动条。(固定表头时要注意自己调节列的宽度)
-
那么此时的startOffset也是直接加到表单数据区(可视区)即可